 Tree Shaking:移除 JavaScript 上下文中的未引用代码
Tree Shaking:移除 JavaScript 上下文中的未引用代码
时至今日,Tree Shaking 对于前端工程师来说,已经不是一个陌生的名词了。顾名思义:Tree Shaking 译为“摇树”,它通常用于描述移除 JavaScript 上下文中的未引用代码(dead-code)。
据我观察,Tree Shaking 也经常出现在诸多候选人的简历当中。然而可惜的是,大部分候选人都知道 Tree Shaking 的定义,但“知其然不知其所以然”,并没有在工程中真正实践过 Tree Shaking 技术,更没有深入理解 Tree Shaking 这个概念。社区上一些好的文章,比如《你的 Tree-Shaking 并没什么卵用》发布于 2018 年初,但就目前来看,其中内容也有些“过期”了。
这一节,就让我们真正深入学习 Tree Shaking 这个概念。
Tree Shaking 必备理论
Tree Shaking 概念很好理解,这个词最先在 Rollup 社区流行,后续蔓延到整个前端生态。Tree Shaking 背后的理论知识独成体系,我们先从其原理入手,试着分析并回答以下问题。
问题一:Tree Shaking 为什么要依赖 ESM 规范?
事实上,Tree Shaking 是在编译时进行无用代码消除的,因此它需要在编译时确定依赖关系,进而确定哪些代码可以被“摇掉”,而 ESM 具备以下特点:
import 模块名只能是字符串常量
import 一般只能在模块的最顶层出现
import binding 是 immutable 的
这些特点使得 ESM 具有静态分析能力。而CommonJS 定义的模块化规范,只有在执行代码后,才能动态确定依赖模块,因此不具备 Tree Shaking 的先天条件。
在传统编译型语言中,一般由编译器将无用代码在 AST(抽象语法树)中删除,而前端 JavaScript 并没有正统“编译器”这个概念,那么 Tree Shaking 就需要在工程链中由工程化工具完成。
问题二:什么是副作用模块,如何对副作用模块进行 Tree Shaking?
如果你熟悉函数式开发理念,可能听说过“副作用函数”,但什么是“副作用模块”呢?它又和 Tree Shaking 有什么关联呢?很多人清楚的 Tree Shaking 只是皮毛,而并不清楚 Tree Shaking 并不能“摇掉”副作用模块,具体我们看这样一段代码:
export function add(a, b) {
return a + b
}
export const memoizedAdd = window.memoize(add)
当该模块被 import 时,window.memoize方法会被执行,那么对于工程化工具(比如 Webpack)来说,分析思路是这样的:
创建一个纯函数
add,如果没有其他模块引用add函数,那么add函数可以被 Tree Shaking 掉;接着调用
window.memoize方法,并传入add函数作为其参数;工程化工具(比如 Webpack)并不知道
window.memoize方法会做什么事情,也许window.memoize方法会调用add函数,并触发某些副作用(比如维护一个全局的 Cache Map);工程化工具(比如 Webpack)为了安全起见,即便没有其他模块依赖的
add函数,那么也要将add函数打包到最后的 bundle 中。
因此,具有副作用的模块难以被 Tree Shaking 优化,即便开发者知道window.memoize方法是无副作用的。
为了解决“具有副作用的模块难以被 Tree Shaking 优化”这个问题,Webpack 给出了自己的方案,我们可以利用 package.json 的sideEffects属性来告诉工程化工具哪些模块具有副作用,哪些剩余模块没有副作用,可以被 Tree Shaking 优化:
{
"name": "your-project",
"sideEffects": false
}
表示全部代码均无副作用,告知 webpack,它可以安全地删除未用到的 export 导出。
{
"name": "your-project",
"sideEffects": [
"./src/some-side-effectful-file.js",
"*.css"
]
}
通过数组表示,./src/some-side-effectful-file.js和所有.css文件模块都有副作用。对于 Webpack 工具,开发者可以在module.rule配置中声明副作用模块。
事实上,仅对上面add函数,即便不通过声明 sideEffects,Webpack 也足够智能,能够分析出可 Tree Shaking 掉的部分,不过这需要我们对上述代码进行重构:
import { memoize } from './util'
export function add(a, b) {
return a + b
}
export const memoizedAdd = memoize(add)
此时 Webpack 的分析逻辑:
memoize函数是一个 ESM 模块,我们去util.js中检查一下memoize函数内容;在
util.js中,发现memoize函数是一个纯函数,因此如果add函数没有被其他模块依赖,可以被安全 Tree Shaking 掉。
所以,我们能得出一个 Tree Shaking 友好的最佳实践——在业务项目中,设置最小化副作用范围,同时通过合理的配置,给工程化工具最多的副作用信息。
下面,我们再来看一个 Tree Shaking 友好的实践案例。
一个 Tree Shaking 友好的导出模式
参考以下代码:
export default {
add(a, b) {
return a + b
}
subtract(a, b) {
return a - b
}
}
以及:
export class Number {
constructor(num) {
this.num = num
}
add(otherNum) {
return this.num + otherNum
}
subtract(otherNum) {
return this.num - otherNum
}
}
对于上述情况,以 Webpack 为例,Webpack 将会趋向保留整个默认导出对象/class(Webpack 和 Rollup 只处理函数和顶层的 import/export 变量,不能把没用到的类或对象内部的方法消除掉)。
因此:
导出一个包含多项属性和方法的对象
导出一个包含多项属性和方法的 class
使用
export default导出
都不利于 Tree Shaking。即便现代化工程工具或 Webpack 支持对于对象或 class 的方法属性剪裁(比如 webpack-deep-scope-plugin 这个插件的设计,或 Webpack 和 Rollup 新版本的跟进),这些都产生了不必要的成本,增加了编译时负担。
我们更加推荐的原则是:原子化和颗粒化导出。如下代码,就是一个更好的实践:
export function add(a, b) {
return a + b
}
export function subtract(a, b) {
return a - b
}
这种方式可以让 Webpack 更好地在编译时掌控和分析 Tree Shaking 信息,取得一个更优的 bundle size。
前端工程生态和 Tree Shaking 实践
通过上述内容,我们可以看出 Tree Shaking 依托于 ESM 静态分析的理论技术,而真正的 Tree Shaking 过程,还需要依靠前端工程工具实现。Tree Shaking 链路当然也就和前端工程生态绑定在一起,我们继续从工程生态层面,分析 Tree Shaking 实践。
Babel 和 Tree Shaking
Babel 已经成为现代化工程和基建方案的必备工具,但是考虑到 Tree Shaking,需要开发者注意:如果使用 Babel 对代码进行编译,Babel 默认会将 ESM 编译为 CommonJS 模块规范。而我们从前面理论知识知道,Tree Shaking 必须依托于 ESM。
为此,我们需要配置 Babel 对于模块化的编译降级,具体配置项在 babel-preset-env#modules 中可以找到。
但既然是“前端工程生态”,那问题就没这么好解决。事实上,如果我们不使用 Babel 将代码编译为 CommonJS 规范的代码,某些工程链上的工具可能就要罢工了。比如 Jest,Jest 是基于 Node.js 开发的,运行在 Node.js 环境。因此使用 Jest 进行测试时,也就需要模块符合 CommonJS 规范,那么如何处理这种“模块死锁”呢?
思路之一是根据不同的环境,采用不同的 Babel 配置。在 production 编译环境中,我们配置:
production: {
presets: [
[
'@babel/preset-env',
{
modules: false
}
]
]
},
}
在测试环境中:
test: {
presets: [
[
'@babel/preset-env',
{
modules: 'commonjs
}
]
]
},
}
但是在测试环境中,编译了业务代码为 CommonJS 规范并没有大功告成,我们还需要处理第三方模块代码。一些第三方模块代码为了方便进行 Tree Shaking,暴露出符合 ESM 模块的代码,对于这些模块,比如 Library1、Library2,我们还需要进行处理,这时候需要配置 Jest:
const path = require('path')
const librariesToRecompile = [
'Library1',
'Library2'
].join('|')
const config = {
transformIgnorePatterns: [
`[\\/]node_modules[\\/](?!(${librariesToRecompile})).*$`
],
transform: {
'^.+\.jsx?$': path.resolve(__dirname, 'transformer.js')
}
}
transformIgnorePatterns是 Jest 的一个配置项,默认值为node_modules,它表示:node_modules中的第三方模块代码,都不需要经过babel-jest编译。因此,我们自定义 transformIgnorePatterns的值为一个包含了 Library1、Library2 的正则表达式即可。
Webpack 和 Tree Shaking
上面我们已经讲解了很多关于 Webpack 处理 Tree Shaking 的内容了,这里我们进一步补充。事实上,Webpack4.0 以上版本在 mode 为 production 时,会自动开启 Tree Shaking 能力。默认 production mode 的配置如下:
const config = {
mode: 'production',
optimization: {
usedExports: true,
minimizer: [
new TerserPlugin({...}) // 支持删除死代码的压缩器
]
}
}
其实,Webpack 真正执行模块去除,是依赖了 TerserPlugin、UglifyJS 等压缩插件。Webpack 负责对模块进行分析和标记,而这些压缩插件负责根据标记结果,进行代码删除。Webpack 在分析时,有三类相关的标记:
harmony export,被使用过的 export 会被标记为 harmony export;
unused harmony export,没被使用过的 export 标记为 unused harmony export;
harmony import,所有 import 标记为 harmony import。
上述标记实现的 Webpack 源码在lib/dependencies/文件中,这里不再进行源码解读了。具体过程主要是:
Webpack 在编译分析阶段,将每一个模块放入 ModuleGraph 中维护;
依靠 HarmonyExportSpecifierDependency 和 HarmonyImportSpecifierDependency 分别识别和处理 import 以及 export;
依靠 HarmonyExportSpecifierDependency 识别 used export 和 unused export。
至此,我们理解了使用 Webpack 进行 Tree Shaking 的原理。接下来,我们再看看著名的公共库都是如何处理 Tree Shaking 的。
Vue 和 Tree Shaking
在 Vue 2.0 版本中,Vue 对象会存在一些全局 API,比如:
import Vue from 'vue'
Vue.nextTick(() => {
//...
})
如果我们没有使用Vue.nextTick方法,那么nextTick这样的全局 API 就成了 dead code,且不容易被 Tree Shaking 掉。为此,在 Vue 3 中,Vue 团队考虑了 Tree Shaking 兼容,进行了重构,全局 API 需要通过原生 ES Module 的引用方式进行具名引用,对应前面的代码,需要:
import { nextTick } from 'vue'
nextTick(() => {
//...
})
除了这些全局 API ,Vue 3.0 也实现了很多内置的组件以及工具的具名导出。这些都是前端生态中,公共库拥抱 Tree Shaking 的表现。
此外,我们也可以灵活使用 build-time flags 来帮助构建工具实现 Tree Shaking。以 WebpackDefinePlugin 为例,下面代码:
import { validateoptions } from './validation'
function init(options) {
if (!__PRODUCTION__) {
validateoptions(options)
}
}
通过__PRODUCTION__变量,在 production 环境下,我们可以将validateoptions函数进行删除。
如何设计一个兼顾 Tree Shaking 和易用性的公共库
上面我们分析了 Vue 拥抱 Tree Shaking 的例子,下面我们应该从另一个更宏观的角度看待这个问题。作为一个公共库的设计者,我们应该如何兼顾 Tree Shaking 和易用性的公共库呢?
试想,如果我们以 ESM 的方式对外暴露代码,那么就很难直接兼容 CommonJS 规范,也就是说在 Node.js 环境中,使用者如果直接以 require 方式引用的话,就会得到报错。如果以 CommonJS 规范对外暴露代码,又不利于 Tree Shaking。
因此,如果想要一个 npm 包既能向外提供 ESM 规范的代码,又能向外提供 CommonJS 规范的代码,我们就只能通过“协约”来定义清楚。实际上,npmpackage.json以及社区工程化规范,解决了这个问题:
{
"name": "Library",
"main": "dist/index.cjs.js",
"module": "dist/index.esm.js",
}
其实,标准 package.json 语法中,只有一个入口main。作为公共库设计者,我们通过main来暴露 CommonJS 规范打包的代码dist/index.cjs.js;在 Webpack 等构建工具中,又支持了module——这个新的入口字段。因此,module并非 package.json 的标准字段,而是打包工具专用的字段,用来指定符合 ESM 标准的入口文件。
这样一来,当require('Library')时,Webpack 会找到:dist/index.cjs.js;当import Library from 'Library'时,Webpack 会找到:dist/index.esm.js。
这里我们不妨举一个著名的公共库例子,那就是 Lodash。Lodash 其实并不支持 Tree Shaking,其package.json:
{
"name": "lodash",
"version": "5.0.0",
"license": "MIT",
"private": true,
"main": "lodash.js",
"engines": {
"node": ">=4.0.0"
},
//...
}
只有一个main入口,且lodash.js是 UMD 形式的代码,不利于做到 Tree Shaking。为了支持 Tree shakibng,lodash 打包出来专门的 lodash-es,其package.json:
{
"main": "lodash.js",
"module": "lodash.js",
"name": "lodash-es",
"sideEffects": false,
//...
}
由上述代码可知,lodash-esmain、module、sideEffects三字段齐全,通过 ESM 导出,天然支持了 Tree Shaking。
总之,万变不离其宗,只要我们掌握了 Tree Shaking 的原理,那么在涉及公共库时,就能做到游刃有余,以各种形式支持到 Tree Shaking。当然,普遍做法是在第三方库打包构建时,参考 antd,一般都会构建出 lib/ 和 es/ 两个文件夹,并配置package.json的main、module字段即可。
CSS 和 Tree Shaking
以上内容都是针对 JavaScript 代码的 Tree Shaking,作为前端工程师,我们当然也要考虑对 CSS 文件做 Tree Shaking。
实现思路也很简单,CSS 的 Tree Shaking 要在样式表中,找出没有被应用到选择器样式,进行删除。那么我们只需要:
遍历所有 CSS 文件的选择器;
根据所有 CSS 文件的选择器,在 JavaScript 代码中进行选择器匹配;
如果没有匹配到,则删除对应选择器的样式代码。
如何遍历所有 CSS 文件的选择器呢?Babel 依靠 AST 技术,完成了对 JavaScript 代码的遍历分析,而在样式世界中,PostCSS 就起到了 Babel 的作用。PostCSS 提供了一个解析器,它能够将 CSS 解析成 AST 抽象语法树,我们可以通过 PostCSS 插件对 CSS 对应的 AST 进行操作,达到 Tree Shaking 的目的。
PostCSS 原理如下图:
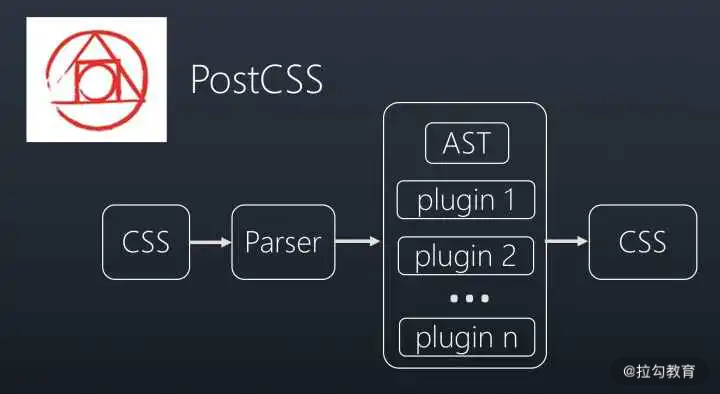
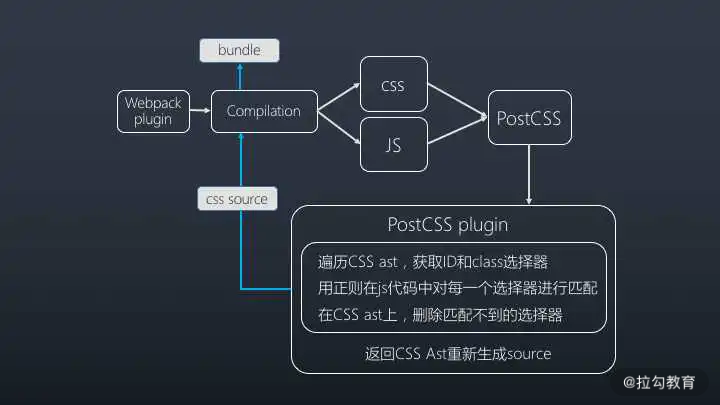
PostCSS 原理图
这里给大家推荐 purgecss-webpack-plugin,其原理也很简单:
监听 Webpack compilation 完成阶段,从 compilation 中找到所有的 CSS 文件(对应源码):
export default class PurgeCSSPlugin {
options: UserDefinedOptions;
purgedStats: PurgedStats = {};
constructor(options: UserDefinedOptions) {
this.options = options;
}
apply(compiler: Compiler): void {
compiler.hooks.compilation.tap(
pluginName,
this.initializePlugin.bind(this)
);
}
//...
}
将所有的 CSS 文件交给 PostCss 处理(源码关键部分,对 CSS AST 应用规则):
public walkThroughCSS(
root: postcss.Root,
selectors: ExtractorResultSets
): void {
root.walk((node) => {
if (node.type === "rule") {
return this.evaluateRule(node, selectors);
}
if (node.type === "atrule") {
return this.evaluateAtRule(node);
}
if (node.type === "comment") {
if (isIgnoreAnnotation(node, "start")) {
this.ignore = true;
// remove ignore annotation
node.remove();
} else if (isIgnoreAnnotation(node, "end")) {
this.ignore = false;
// remove ignore annotation
node.remove();
}
}
});
}
利用 PostCss 插件能力,基于 AST 技术,找出无用代码并进行删除。
核心删除未使用 CSS 代码的逻辑在purge 方法中,这里我们不再展开。
总结
本小节,我们分析了 Tree Shaking 相关知识,我们发现这一理论内容还需要配合构建工具完成落地,而这一系列过程不只是想象中那样简单。
这里我想给你留一个思考题,Rollup 是如何实现 Tree Shaking 的呢?欢迎在留言区和我分享你的观点。
更多内容,我们会结合下一讲“如何理解 AST 实现和编译原理?”,带你实现一个真实的 AST 的落地场景,完成一个简易版 Tree Shaking 实现。我们下一讲再见!
# 精选评论
# **铭
写的很好
# **7269
那个裁剪css的插件,我们业务中很多动态class,貌似只能配置白名单了
# *萱
有些html中的css类是js动态生成的,那岂不是把一些css给摇树掉了?
# 讲师回复
不会,会根据 js 进行分析
# **3336
是不是UMD模块代码做不到TreeShaking?
# 讲师回复
是
# *威
import现在不一定在最顶层鸭
# 讲师回复
static import vs dynamic import
# **平
问一下,如果项目里有一个包不支持 Tree Shaking,那打包时整个项目时,除了这个不支持的包以为,其他包都是用Tree Shaking打包吗?
# 讲师回复
是,但得看你配置和实现