 Event Loop
Event Loop
https://www.jsv9000.app/
# 面试标准答案
一. 浏览器
- 一开始整段脚本作为第一个宏任务执行
- 执行过程中同步代码直接执行,宏任务进入宏任务队列,微任务进入微任务队列
- 当前宏任务执行完出队,检查微任务队列,如果有则依次执行,直到微任务队列为空
- 执行浏览器 UI 线程的渲染工作
- 检查是否有 Web worker 任务,有则执行
- 执行队首新的宏任务,回到 2,依此循环,直到宏任务和微任务队列都为空
二. node
(1). timer 阶段(node11 版本以后和浏览器一样,11 之前的有区别。例如:setTimeout、setInterval 的回调)
(2). I/O 异常回调阶段
(3). poll 轮询阶段
如果当前已经存在定时器,而且有定时器到时间了,拿出来执行,eventLoop 将回到 timer 阶段
如果没有定时器, 会去看回调函数队列
1), 如果队列不为空,拿出队列中的方法依次执行
2), 如果队列为空,检查是否有 setImmdiate 的回调,有则前往 check 阶段.没有则继续等待,相当于阻塞了一段时间(阻塞时间是有上限的)
(4). check 阶段(执行 setImmdiate 的回调)
(5). 关闭事件的回调阶段(一些关闭的回调函数,如:socket.on('close', ...))

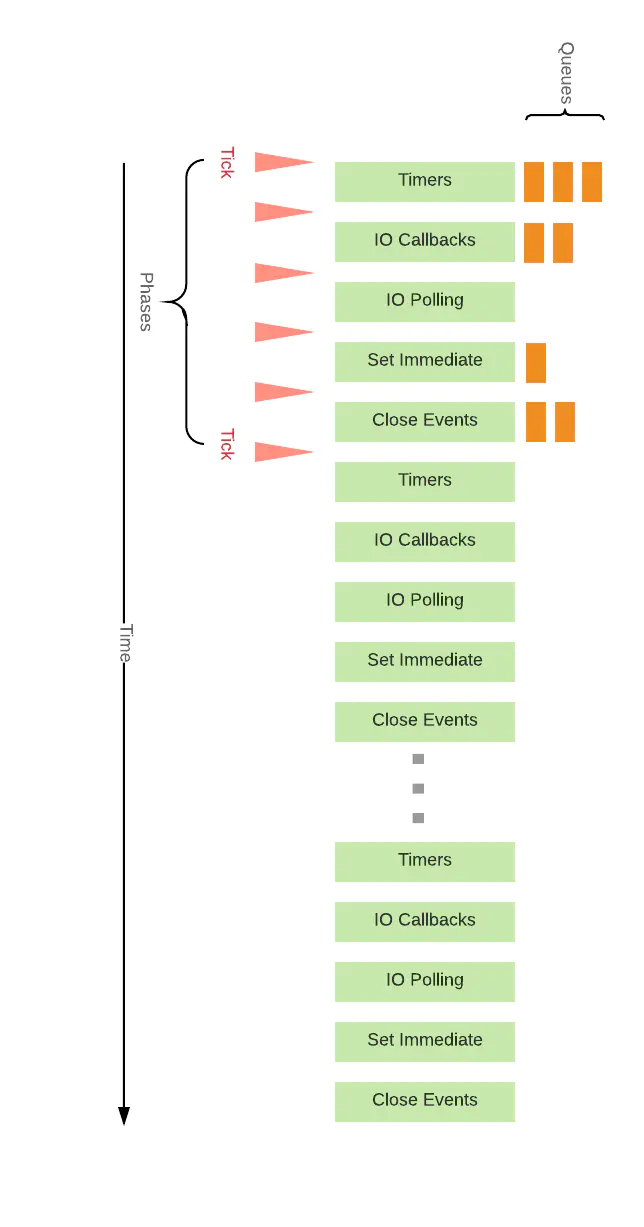
# node11 之前和 node11 之后比较
setTimeout(() => {
console.log(1);
new Promise((resolve, reject) => {
resolve();
}).then(() => {
console.log(2);
});
setTimeout(() => {
console.log(6);
}, 0);
}, 0);
setTimeout(() => {
console.log(3);
new Promise((resolve, reject) => {
resolve();
}).then(() => {
console.log(4);
});
}, 0);
new Promise((resolve, reject) => {
resolve();
}).then(() => {
console.log(5);
setTimeout(() => {
console.log(7);
}, 0);
});
node11 之前答案 5132476
node11 之后答案 5123476
# 解析
两者最主要的区别在于浏览器中的微任务是在每个相应的宏任务中执行的,而 nodejs 中的微任务是在不同阶段之间执行的。
若第一个定时器任务出队并执行完,发现队首的任务仍然是一个定时器,那么就将微任务暂时保存,直接去执行新的定时器任务,当新的定时器任务执行完后,再一一执行中途产生的微任务。
process.nextTick 是一个独立于 eventLoop 的任务队列。
在每一个 eventLoop 阶段完成后会去检查这个队列,如果里面有任务,会让这部分任务优先于微任务执行
https://sanyuan0704.top/my_blog/blogs/javascript/js-v8/006.html#_3-实例演示 (opens new window)
// 11之前
let marquenePre = [1, 3];
let mirquenePre = [];
let marqueneAtf = [];
let mirqueneAtf = [];
function eventloop() {
while (marquenePre.length > 0 || mirquenePre.length > 0) {
let task;
if (mirquenePre.length > 0) {
task = mirquenePre.shift();
task(); // task可能存在marqueneAtf.push(task),marqueneAtf.push(task)
eventloop();
break;
}
if (marquenePre.length > 0) {
task = marquenePre.shift();
task();
eventloop();
break;
}
}
if (marquenePre.length === 0 && marquenePre.length === 0) {
marquenePre = [...marqueneAtf];
mirquenePre = [...marqueneAtf];
marqueneAtf = marqueneAtf = [];
}
}
// 11之后
let marquene = [];
let mirquene = [];
function eventloop() {
while (mirquene.length > 0 || marquene.length > 0) {
let task;
if (mirquene.length > 0) {
task = mirquene.shift();
task(); // task可能存在marquen.push(task),mirquene.push(task)
eventloop();
break;
}
if (marquene.length > 0) {
task = marquene.shift();
task();
eventloop();
break;
}
}
}
# 为什么会出现事件循环
js 是单线程的,一次只能运行一个任务。
为什么是单线程?
- 设计之初没有这样的需求,起初 js 只是脚本语言能做的事情很少,并且多线程会增加复杂性和内存消耗,所以单线程足以。这点在 node 上也有体现,node 默认只能调用 2g 的内存,其实也间接说明了 js 的应用场景的限制
- 防止两个线程同时操作 dom 的冲突,解决冲突会让浏览器变得更复杂
- js 目前也是支持多线程的,不过除了主线程其他线程都是不能操作 dom 的,这也间接印证了前面的两点,除了 dom 的操作冲突,其实用多线程挺好用的。多线程一般用于需要消耗时间的计算操作。
如果是单线程,遇到一个耗时的任务,则阻塞太长。所以出现了时间循环机制
浏览器为我们提供了 JavaScript 引擎本身不提供的一些功能:Web API。这包括 DOM API,setTimeout,HTTP 请求等。这可以帮助我们创建一些异步的,非阻塞的行为。
# 动图理解
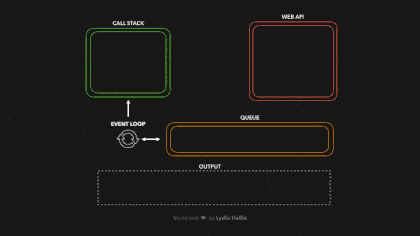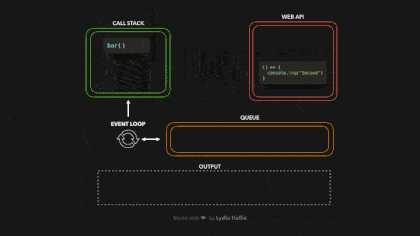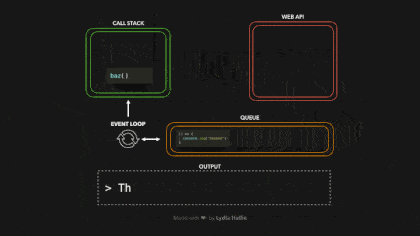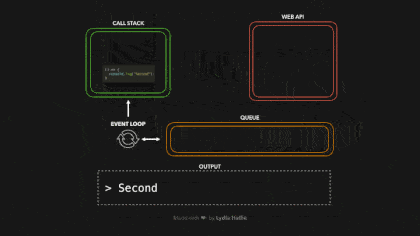
当我们调用一个函数时,它会被添加到一个叫做调用栈的东西中。调用堆栈是 JS 引擎的一部分,这与浏览器无关。它是一个堆栈,意味着它是先入后出的(想想一堆薄饼)。当一个函数返回一个值时,它被从堆栈中弹出。
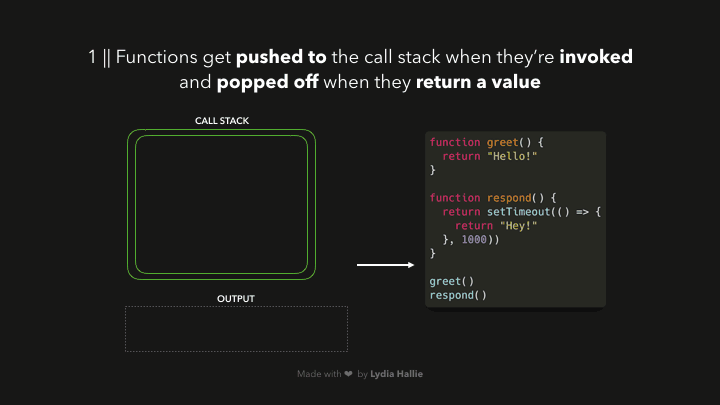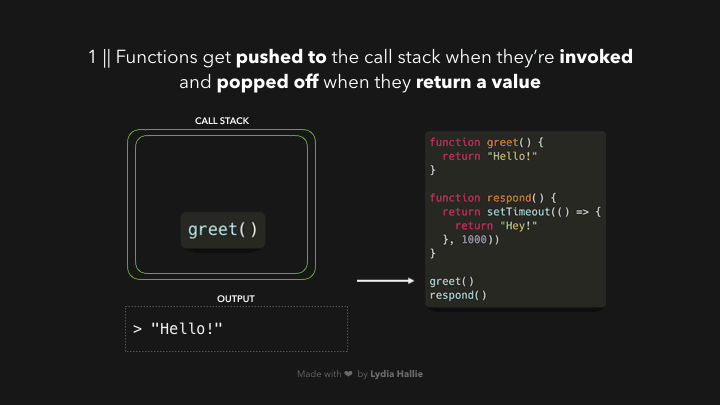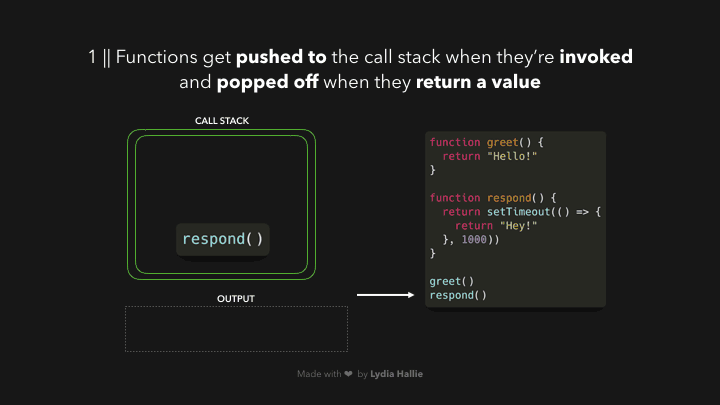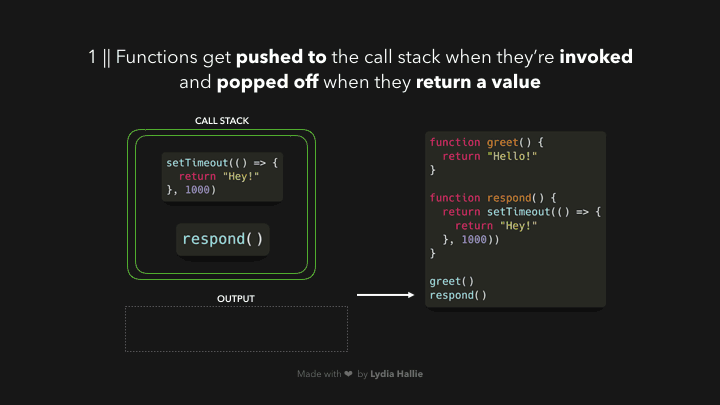
响应函数返回一个 setTimeout 函数。setTimeout 是由 Web API 提供给我们的:它让我们在不阻塞主线程的情况下延迟任务。我们传递给 setTimeout 函数的回调函数,箭头函数()=> { return 'Hey' }被添加到 Web API 中。同时,setTimeout 函数和 response 函数被从堆栈中弹出,它们都返回了它们的值!
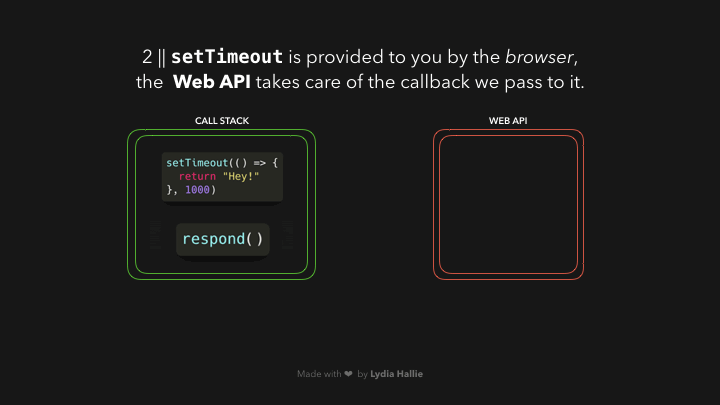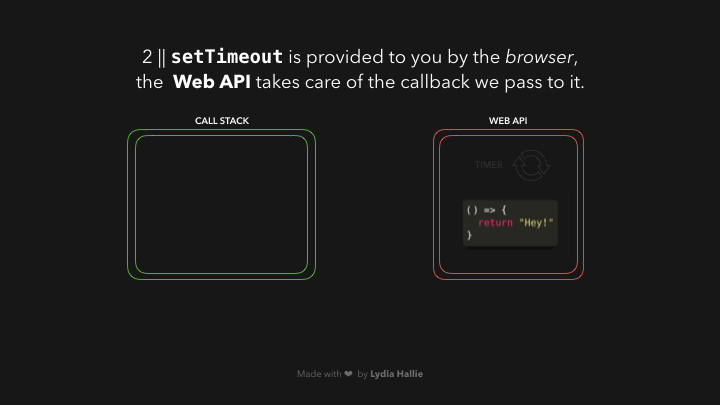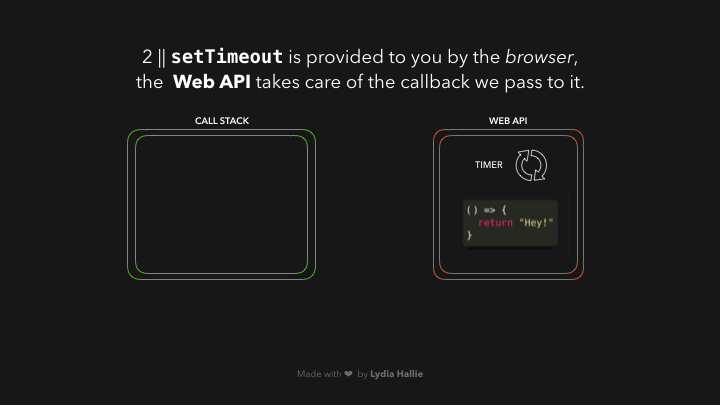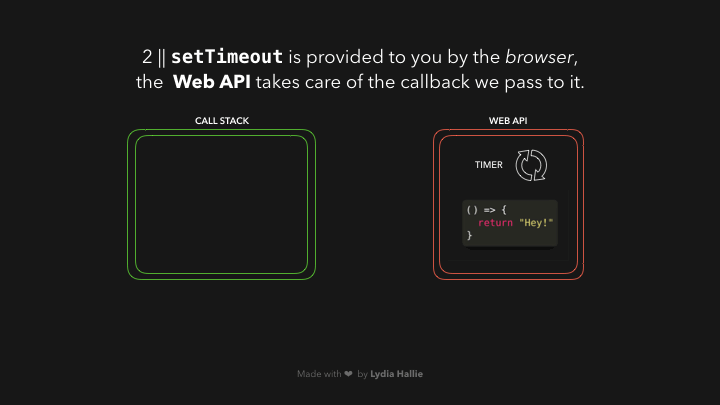
在 Web API 中,定时器的运行时间与我们传递给它的第二个参数一样长,即 1000ms。回调并不立即被添加到调用栈中,而是被传递到一个叫做队列的东西中
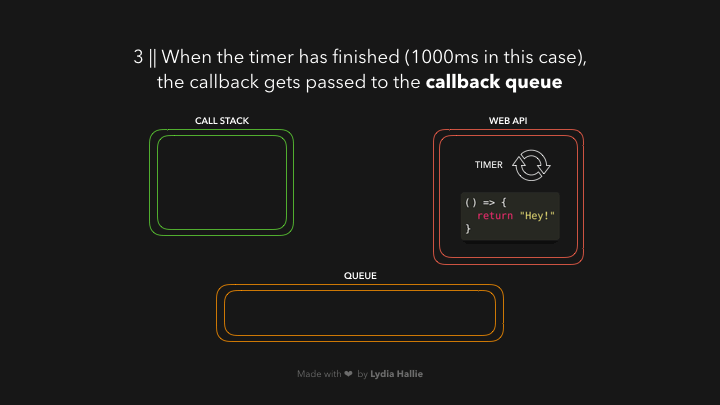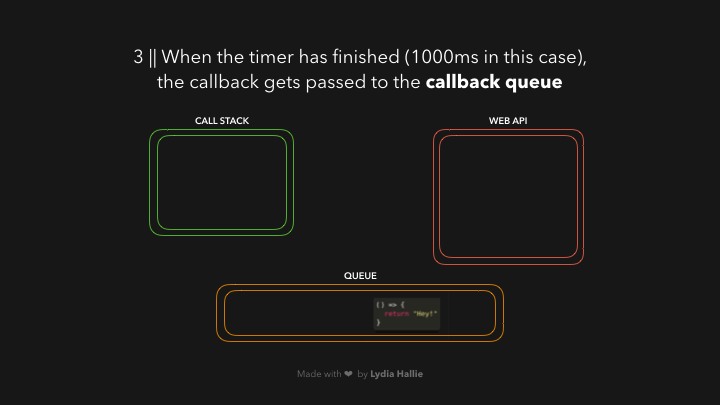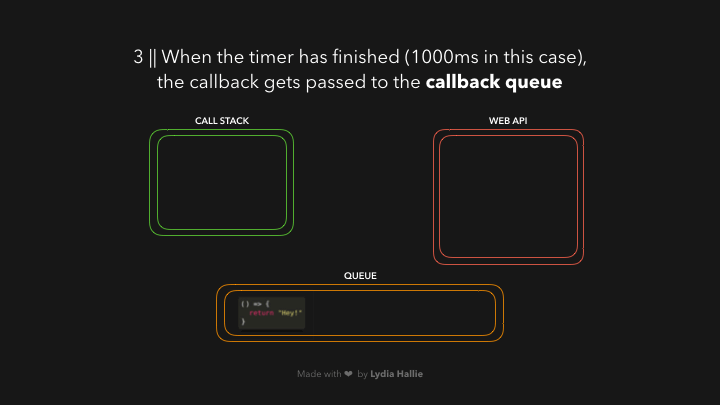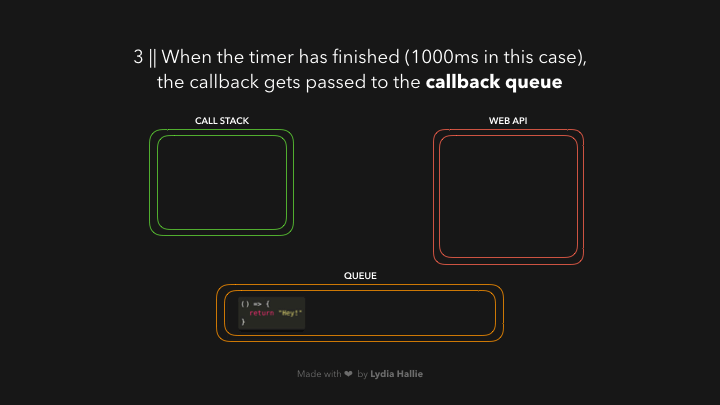
现在是我们一直在等待的部分,是时候让事件循环完成它唯一的任务了:将队列和调用栈连接起来。如果调用栈是空的,那么如果所有先前调用的函数都已经返回了它们的值,并且已经从栈中弹出,那么队列中的第一个项目就会被添加到调用栈中。在这种情况下,没有其他函数被调用,也就是说,当回调函数成为队列中的第一项时,调用栈是空的。
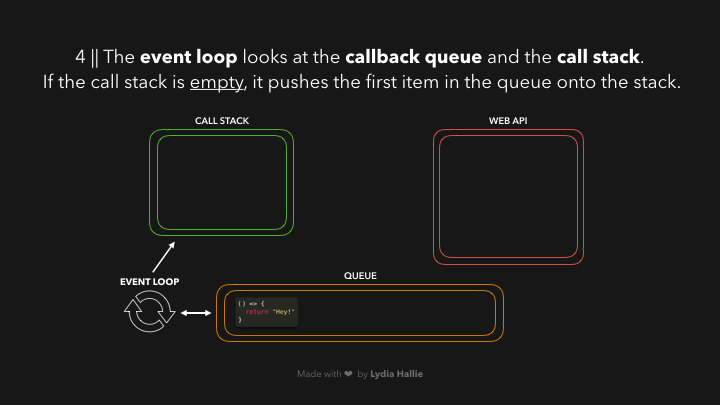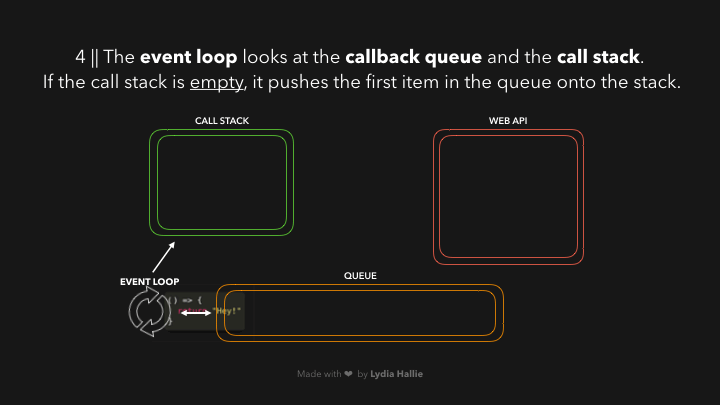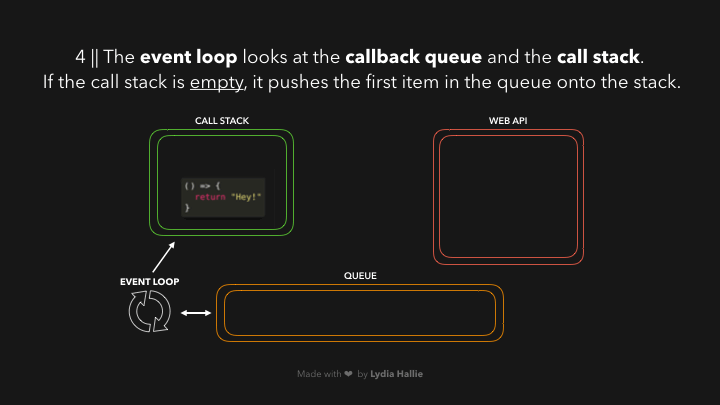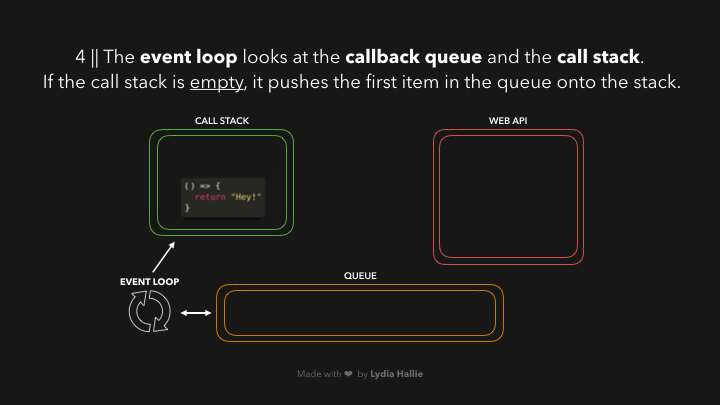
回调被添加到调用堆栈,被调用,并返回一个值,然后被从堆栈中弹出,如图

# 例子
const foo = () => console.log("First");
const bar = () => setTimeout(() => console.log("Second"), 500);
const baz = () => console.log("Third");
bar();
foo();
baz();
虽然看起来很简单,嗯,可以尝试搞一下:
打开我们的浏览器,跑一下上面的代码,让我们快速看一下在浏览器中运行此代码时发生的情况:
# 例题
async function async1() {
console.log("1");
await async2();
console.log("2");
}
async function async2() {
console.log("3");
}
console.log("4");
setTimeout(() => {
console.log("5");
}, 0);
async1();
new Promise((resolve) => {
console.log("6");
resolve();
}).then(function() {
console.log("7");
});
console.log("8");
41368275