 设计性能守卫系统:完善 CICD 流程
设计性能守卫系统:完善 CICD 流程
性能始终是宏大的话题,前面几讲我们或多或少都有涉及性能优化的各种方案。其实,除了传统的性能优化手段以外,我们还需要对性能进行把关,目的是在性能恶化时有所感知、有所防控。那么,一个性能守卫系统即性能监控系统究竟应该如何设计呢?
借助 Node.js 的能力,这一讲我们就下钻到 CI/CD 流程,设计一个性能守卫系统。希望通过这一讲的学习,你可以认识到:Node.js 除了同构直出、数据聚合以外,还能做一些重要的,且有趣的服务。
性能守卫理论基础
性能守卫的含义是:对每次上线进行性能把关,对性能恶化做到提前预警。它包含了一个性能监控平台,同时也需要给出更多的性能建议和指标建设。
那么我们如何感知到性能的好坏呢?我们对于 Load/DOMContentLoaded 事件、FP/FCP 指标已经耳熟能详了,下面我们再扩充几个更加现代化的指标。
LCP(Largest Contentful Paint)
衡量页面的加载体验,它表示视口内可见的最大内容元素的渲染时间。相比 FCP,这个指标可以更加真实地反映具体内容加载速度。比如,如果页面渲染前有一个 loading 动画,那么 FCP 可能会以 loading 动画出现的时间为准,而 LCP 定义了 loading 动画加载后,真实渲染出内容的时间。
FID(First Input Delay)
衡量可交互性,它表示用户和页面进行首次交互操作所花费的时间。它比 TTI(Time to Interact)更加提前,这个阶段虽然页面已经显示出部分内容,但并不能完全具备可交互性,对于用户的响应可能会有较大的延迟。
CLS(Cumulative Layout Shift)
衡量视觉稳定性,表示页面的整个生命周期中,发生的每个意外的样式移动的所有单独布局更改得分的总和。所以这个分数当然越小越好。
以上是几个重要的、现代化的性能指标。结合我们传统的 FP/FCP/FMP 时间等,我们可以构建出一个相对完备的指标系统。这里我们就不再一一分析如何获取和收集这些性能指标了,相关内容社区上有不少文章。我们把目光放到更高层面,请你思考一下:如何从这些指标中,得到监控素材?
业界公认的监控素材主要由两方面提供:
真实用户监控(Real User Monitoring,RUM)
合成监控(Synthetic Monitoring,SYN)
真实用户监控是基于用户真实访问应用情况,在应用生命周期内计算产出性能指标,并进行上报。开发者拉取日志服务器上的指标数据,进行清洗加工,最终生成真实的访问监控报告。
真实用户监控一般搭配稳定的 SDK,会在一定程度上影响用户的访问性能,也给用户带来了额外的流量消耗。
合成监控是一种实验室数据,它指的是在某一个模拟场景中,通过工具,搭配规则和性能审计条目,得到一个合成的监控报告。
合成监控的优点比较明显,它的实现比较简单,有现成成熟的解决方案;如果搭配丰富的场景和规则,得到的数据类型也会较多。但它的缺点是数据量相对较小,且模拟条件配置相对复杂,无法完全反映真实场景。
而在 CI/CD pipeline 上,我们需要设计的性能守卫方案就是一种合成监控方案。在方案设计上,我们需要做到扬长避短。
Lighthouse 原理介绍
前文提到,合成监控有成熟的方案,比如 Lighthouse。我们的方案也基于 Lighthouse 进行,这里对 Lighthouse 原理进行介绍。
Lighthouse 是一个开源的自动化工具,它提供了四种使用方式,分别是:
Chrome DevTools
Chrome 插件
Node cli
Node module
我们先通过 Chrome DevTools 来迅速体验一下 Lighthouse。在 Audits 面板下,进行相关测试,可以得到一个网址的相关测试报告,内容如下图:

这个报告是如何得出的呢?我们先来看 Lighthouse 的架构图:
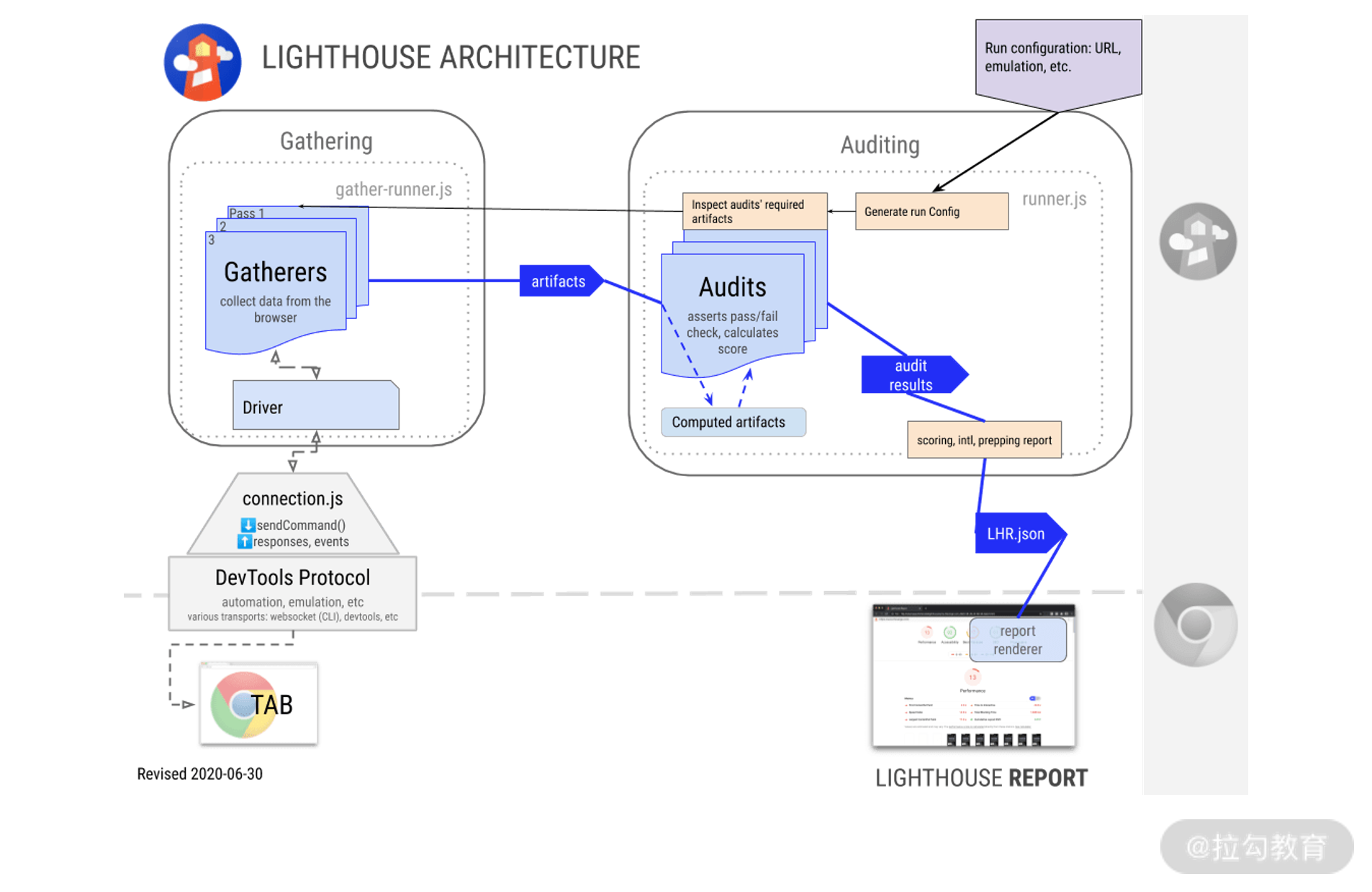
Lighthouse 架构图
图中的一些关键名词:
Driver(驱动器),根据Chrome Debugging Protocol协议与浏览器交互的对象;
Gatherers(采集器),调用 Driver 运行浏览器命令后得到的网页基础信息,每个采集器都会收集自己的目标信息,并生成中间产物(Artifacts);
Artifacts(中间产物),一系列 Gatherers 的集合,会被 Audits 使用,并计算得分;
Audits(审计项),以 Artifacts 作为输入,进行性能测试并评估分数后得到的 LHAR(LightHouse Audit Result Object)标准数据对象。
我们结合上述名词,对 Lighthouse 架构原理进行分析:
首先,Lighthouse 驱动 Driver,底层通过 Chrome DevTool Protocol 调用浏览器进行应用的加载和渲染;
然后通过 Gatherers 模块集合,获取收集到的 Artifacts 信息;
Artifacts 信息在 Auditing 阶段,通过对自定义指标的审计,得到 Audits 结果,并生成相关文件。
从该流程中我们可以得到的关键信息:
Lighthouse 会与浏览器建立连接,并通过 CDP 与浏览器进行交互;
通过 Lighthouse,我们可以自定义审计项并得到审计结果。
在我们的性能守卫系统中,是采用 Lighthouse 的后两种使用方式(Node.js cli/ Node.js 模块)进行性能跑分的,下面代码给出一个基本的使用方式:
const fs = require('fs');
const lighthouse = require('lighthouse');
const chromeLauncher = require('chrome-launcher');
(async () => {
// 启动一个 chrome,
const chrome = await chromeLauncher.launch({chromeFlags: ['--headless']});
const options = {logLevel: 'info', output: 'html', onlyCategories: ['performance'], port: chrome.port};
// 使用 lighthouse 对目标页面进行跑分
const runnerResult = await lighthouse('https://example.com', options);
// `.report` 是一个 html 类型的分析页面
const reportHtml = runnerResult.report;
fs.writeFileSync('lhreport.html', reportHtml);
// `.lhr` 是用于 lighthous-ci 的结果集合
console.log('Report is done for', runnerResult.lhr.finalUrl);
console.log('Performance score was', runnerResult.lhr.categories.performance.score * 100);
await chrome.kill();
})();
上面的代码描述了一个简单的 Node.js 环境使用 Lighthouse 的场景。其中提到了 lighthous-ci,这是官方给出的 CI/CD 过程接入 Lighthouse 的方案。但一般在企业中,CI/CD 过程相对敏感,我们的性能守卫系统就需要在私有前提下,介入 CI/CD 流程,本质上来说是实现一个专有的 lighthous-ci。
性能守卫系统:Perf-patronus
我们暂且给性能守卫系统起名为 Perf-patronus,寓意为性能-护卫神。
预计 Perf-patronus 会默认监控以下性能指标:
FCP
Total Blocking Time
First CPU Idle
TTI
Speed Index
LCP
其工作架构和流程如下图所示:
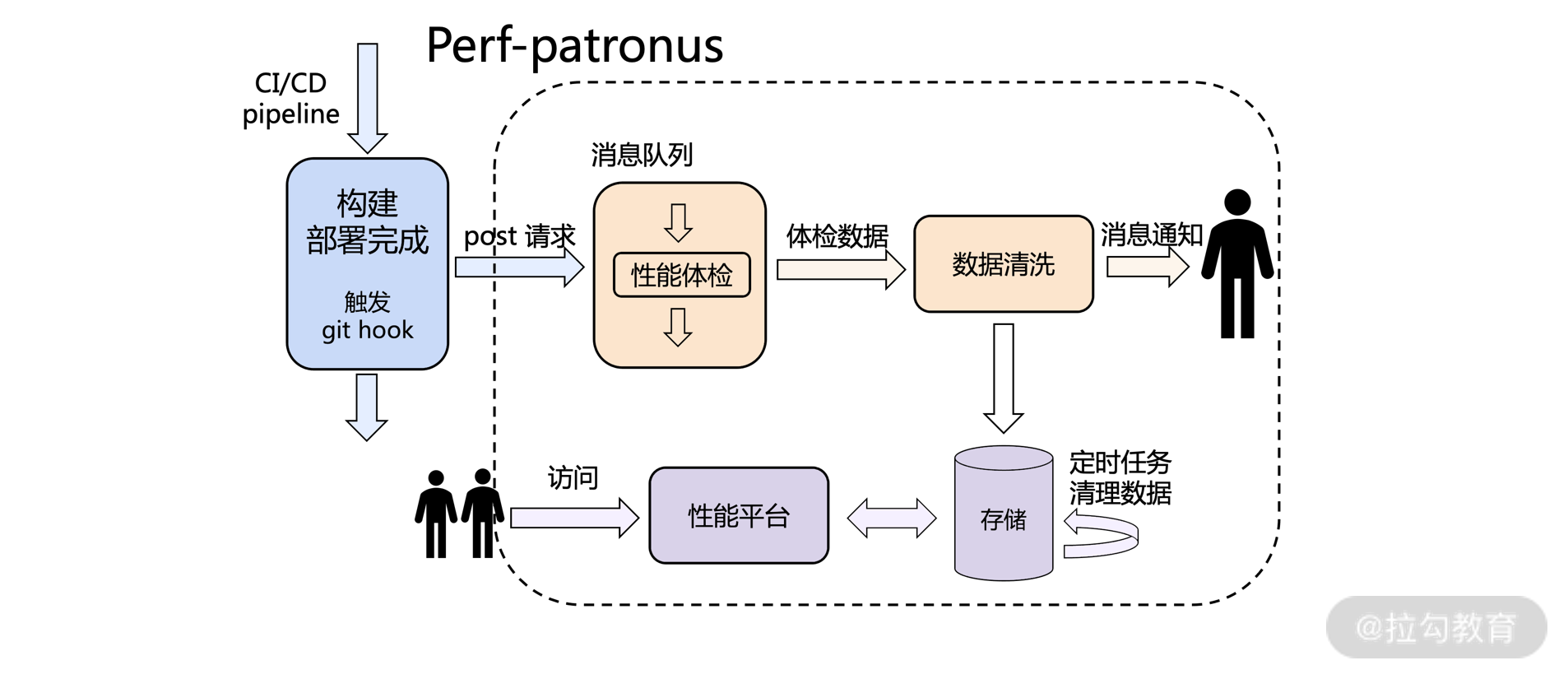
Perf-patronus 工作架构及流程图
特定环境完成 MR 部署后,开始进行性能体检服务。
性能体检服务由消息队列 worker 消费完成。
每一次性能体检产出体检数据,根据数据内容是否达标,进行后续消息提醒;体检数据内容同时被性能守卫系统平台所消费,展现相关页面的性能情况。
性能数据由 Redis 存储。
性能体检相关富媒体资源(页面截图等)可以由容器持久化目录存储,或上传到 OSS 服务
预计平台使用情况,如下图所示:
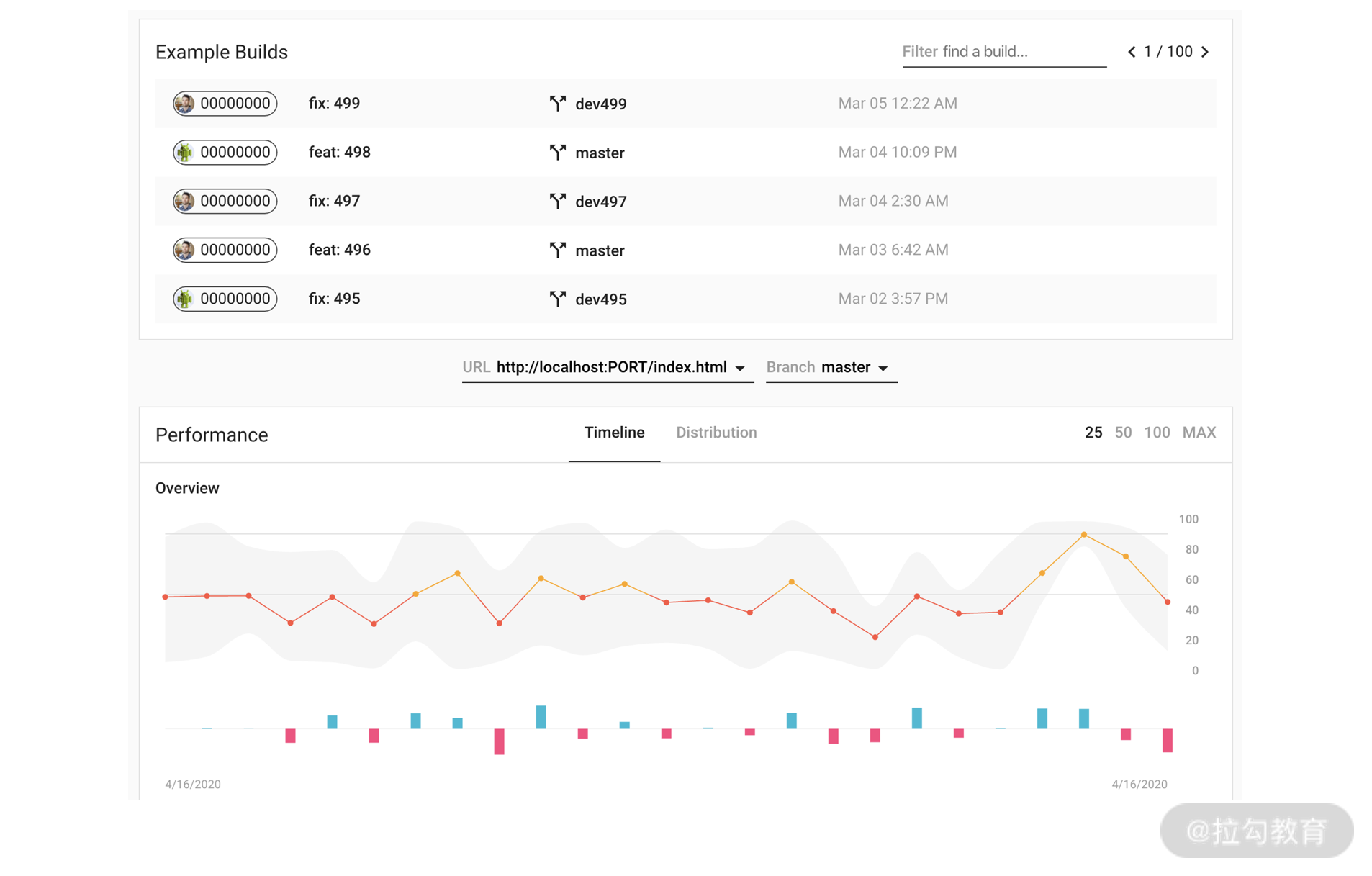
技术架构流程相对清晰,但我们需要思考一个重要的问题:如何真实反映用户情况?并以此为出发点,完善性能守卫系统的相关设计。
如何真实反映用户情况?
真实用户访问页面的情况千变万化,即便我们的代码没有变化,其他可变因素也会大量存在。因此我们应该统一共识一个相对稳定可靠的性能评判标准,其中关键一环是分析可能出现的可变因素,对每一类可变因素进行不同针对性设计,保证每次性能服务产出结果的说服力和稳定性。
常见不确定和波动因素
页面不确定性
比如 A/B 实验情况。这种情况性能体检服务无法进行处理,需要接入者保证页面性能的可对比性。
用户侧网络情况不确定性
针对这种情况,性能体检服务应该设计有可靠的 Throttling 机制,以及较合理的请求等待时间。
终端设备不确定性
性能体检服务应该设计有可靠的 CPU Simulating 能力,并统一 CPU 能力测试范围标准。
页面服务器不稳定性
这方面因素影响较小,应该不用过多考虑。对于服务挂掉的情况,反映出性能异常即可。性能体检服务的稳定性
在同一台机器上,如果不确定有其他应用服务,会影响性能体检服务的稳定性和一致性。不过预计该影响因素不大,可以通过模拟网络环境和 CPU 能力,来保障性能体检服务的稳定性和一致性。
在对性能服务的跑分设计时,都需要考虑上述可变因素,大体上我们可以通过以下手段,最大化地磨平差异:
保证性能体检服务的硬件/容器能力;
需要接入者清楚代码或页面变动对页面性能可能产生的影响,并做好相应接入侧处理;
自动化重复多次跑性能服务,取平均值;
模拟多种网络/终端情况,设计得分权重。
如何解决有“用户态”页面的鉴权问题?
对于有登录状态的页面,我们提供以下几种方案进行登录状态的性能服务:
通过Puppeteer page.cookie,测试时通过 script 实现登录态;
通过请求服务时,传递参数解决登录态问题。
整体流程
下面我们通过代码来串联整个流程。入口任务:
async run(runOptions: RunOptions) {
// 检查相关数据
const results = {};
// 使用 Puppeteer 创建一个无头浏览器
const context = await this.createPuppeteer(runOptions);
try {
// 执行必要的登录流程
await this.Login(context);
// 页面打开前的钩子函数
await this.before(context);
// 打开页面,获取 lighthouse 数据
await this.getLighthouseResult(context);
// 页面打开后的钩子函数
await this.after(context, results);
// 收集页面性能数据
return await this.collectArtifact(context, results);
} catch (error) {
throw error;
} finally {
// 关闭页面和无头浏览器
await this.disposeDriver(context);
}
}
其中,创建一个 Puppeteer 无头浏览器的逻辑,如下代码:
async createPuppeteer (runOptions: RunOptions) {
// 启动配置项可以参考 [puppeteerlaunchoptions](https://zhaoqize.github.io/puppeteer-api-zh_CN/#?product=Puppeteer&version=v5.3.0&show=api-puppeteerlaunchoptions)
const launchOptions: puppeteer.LaunchOptions = {
headless: true, // 是否采用无头模式
defaultViewport: { width: 1440, height: 960 }, // 指定页面视口宽高
args: ['--no-sandbox', '--disable-dev-shm-usage'],
// Chromium 安装路径
executablePath: 'xxx',
};
// 创建一个浏览器对象
const browser = await puppeteer.launch(launchOptions);
const page = (await browser.pages())[0];
// 返回浏览器和页面对象
return { browser, page };
}
打开相关页面,并执行 Lighthouse 模块,如下代码所示:
async getLighthouseResult(context: Context) {
// 获取上下文信息,包括 browser 和页面地址
const { browser, url } = context;
// 使用 lighthouse 模块进行性能采集
const { artifacts, lhr } = await lighthouse(url, {
port: new URL(browser.wsEndpoint()).port,
output: 'json',
logLevel: 'info',
emulatedFormFactor: 'desktop',
throttling: {
rttMs: 40,
throughputKbps: 10 * 1024,
cpuSlowdownMultiplier: 1,
requestLatencyMs: 0,
downloadThroughputKbps: 0,
uploadThroughputKbps: 0,
},
disableDeviceEmulation: true,
// 只检测 performance 模块
onlyCategories: ['performance'],
});
// 回填数据
context.lhr = lhr;
context.artifacts = artifacts;
}
上述流程都是常规启用 Lighthouse 模块,在 Node.js 环境中对相关页面执行 Lighthouse 的逻辑。
我们自定义的逻辑往往可以通过 Lighthouse 插件实现,一个 Lighthouse 插件就是一个 Node.js 模块,在插件中我们可以定义 Lighthouse 的检查项,并在产出报告中以一个新的 category 呈现。
举个例子,我们想要实现“检查页面中是否含有大小超过 5MB 的 GIF 图片”的任务,如以下代码:
module.exports = {
// 对应 audits
audits: [{
path: 'lighthouse-plugin-cinememe/audits/cinememe.js',
}],
// 该 plugin 对应的 category
category: {
title: 'Obligatory Cinememes',
description: 'Modern webapps should have cinememes to ensure a positive ' +
'user experience.',
auditRefs: [
{id: 'cinememe', weight: 1},
],
},
};
对应自定义 Audits,如下代码:
'use strict';
const Audit = require('lighthouse').Audit;
// 继承 Audit 类
class CinememeAudit extends Audit {
static get meta() {
return {
id: 'cinememe',
title: 'Has cinememes',
failureTitle: 'Does not have cinememes',
description: 'This page should have a cinememe in order to be a modern ' +
'webapp.',
requiredArtifacts: ['ImageElements'],
};
}
static audit(artifacts) {
// 默认 hasCinememe 为 false(大小超过 5MB 的 GIF 图片)
let hasCinememe = false;
// 非 Cinememe 图片结果
const results = [];
// 过滤筛选相关图片
artifacts.ImageElements.filter(image => {
return !image.isCss &&
image.mimeType &&
image.mimeType !== 'image/svg+xml' &&
image.naturalHeight > 5 &&
image.naturalWidth > 5 &&
image.displayedWidth &&
image.displayedHeight;
}).forEach(image => {
if (image.mimeType === 'image/gif' && image.resourceSize >= 5000000) {
hasCinememe = true;
} else {
results.push(image);
}
});
const headings = [
{key: 'src', itemType: 'thumbnail', text: ''},
{key: 'src', itemType: 'url', text: 'url'},
{key: 'mimeType', itemType: 'text', text: 'MIME type'},
{key: 'resourceSize', itemType: 'text', text: 'Resource Size'},
];
return {
score: hasCinememe > 0 ? 1 : 0,
details: Audit.makeTableDetails(headings, results),
};
}
}
module.exports = CinememeAudit;
通过上面插件,我们就可以在 Node.js 环境中,结合 CI/CD 流程,找出页面中大小超过 5MB 的 GIF 图片了。
由插件原理可知,一个性能守卫系统,是通过常规插件和自定义插件集合而成的,具有良好的扩展性。
总结
这一讲我们通过一个性能守卫系统,拓宽了 Node.js 的应用场景。我们需要对性能话题有一个更现代化的理论认知:传统的性能指标数据依然重要,但是现代化的性能指标数据也在很大程度上反映了用户体验。我们也应该通过学习,了解 Lighthouse 架构及其原理,并能通过 Lighthouse 插件进行自定义扩展,实现我们自主的性能指标考量。
本讲内容总结如下:
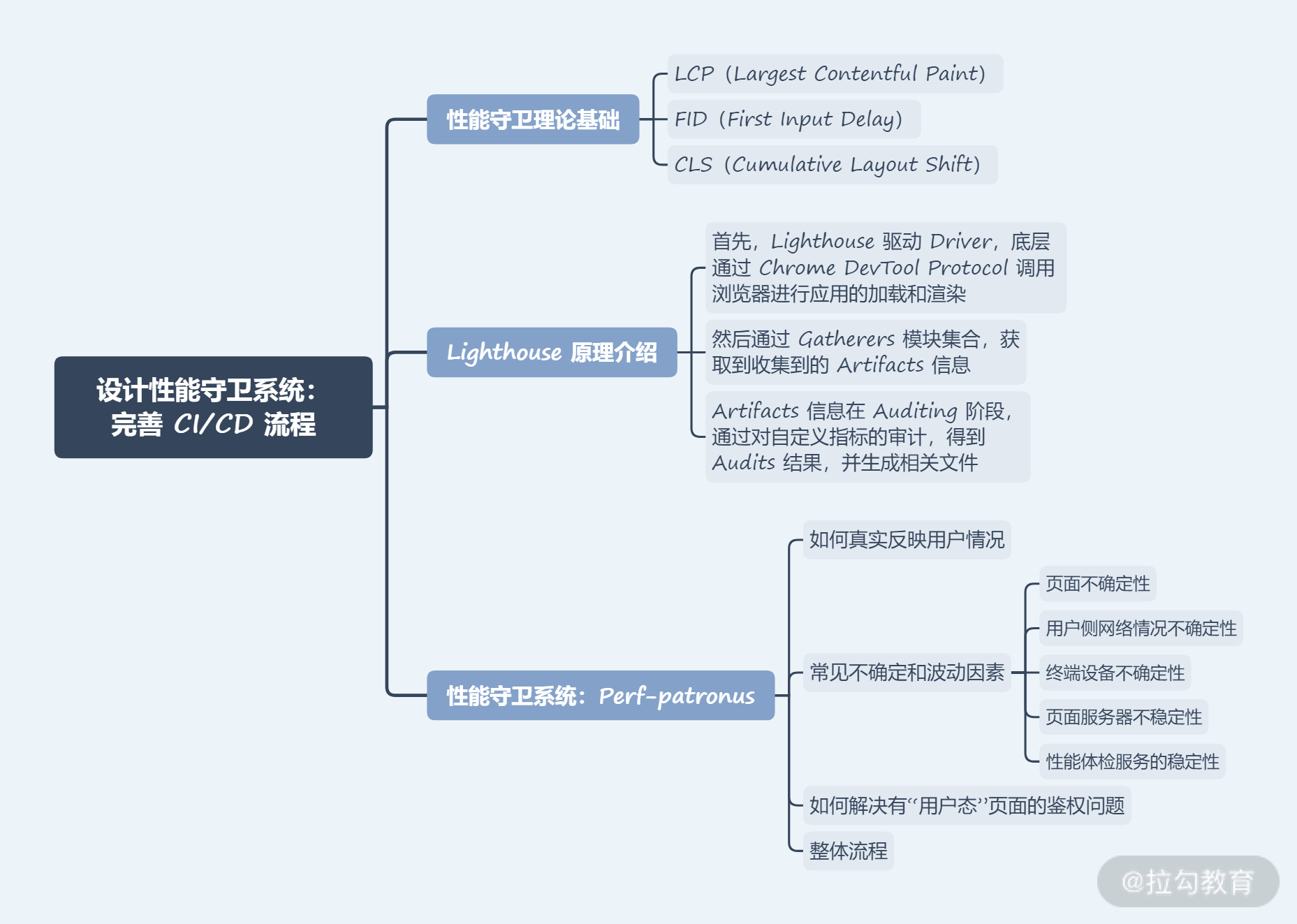
一方面,性能知识把基于 Lighthouse 的 Node.js 相关模块搬上 CI/CD 系统,这样一来我们能够守卫每一次上线,分析每一次上线对性能产生的影响——这是非常重要的实践。任何能力和扩展如果只是在本地,或通过 Chrome 插件的形式尝鲜显然是不够的,借助于 Node.js,我们能做到更多。
下一讲,我们将深入讲解 Node.js 另外一个重要的应用场景:企业级 BFF 网关。网关这个话题可以和微服务、Serverless 等概念相结合,想象空间无限大;同时我们又要深入到网关实现代码,抽丝剥茧,请你做好准备。