 横向对比主流构建工具,了解构建工具的设计考量
横向对比主流构建工具,了解构建工具的设计考量
现代化前端架构离不开构建工具的加持。构建工具的选择、理解和应用决定了是否能够打造一个流畅且接近完美的开发体验。这一讲,我们通过“横向对比构建工具”这个非常新颖的角度,来了解构建工具背后的架构理念。
提到构建工具,作为经验丰富的前端开发者,相信你能列举出不同时代的代表:从 Browserify + Gulp 到 Parcel,从 Webpack 到 Rollup,甚至尤雨溪最近编写的 Vite,相信你也并不陌生。没错,前端发展到现在,构建工具琳琅满目,且已经成熟稳定下来。但这些构建工具的实现和设计非常复杂,甚至出现了“面向构建工具编程”的调侃。
事实上,能够熟悉并精通构建工具的开发者凤毛麟角。请注意,这里的“熟悉并精通”并不是要求你对不同构建工具的配置项目如数家珍,而是真正能把握构建流程。在“6 个月就会出现一批新的技术潮流”的前端领域,能始终把握构建工具的奥秘——这也是区分资深架构师和程序员的一个重要标志。

如何真正了解构建流程,甚至能够自己开发一个构建工具呢?这里我先通过横向比较不同构建工具,让你有一个整体的把控和认知,能够明白构建工具要做什么、怎么做。
从 Tooling.Report 中,我们能学到什么
Tooling.Report 是由 Chrome core team 核心成员以及业内著名开发者打造的构建工具比对平台,其对应 GitHub 地址为:GoogleChromeLabs tooling.report。
这个平台对比了 Webpack v4、Rollup v2、Parcel v2、Browserify + Gulp 在不同维度下的表现,如下图所示:
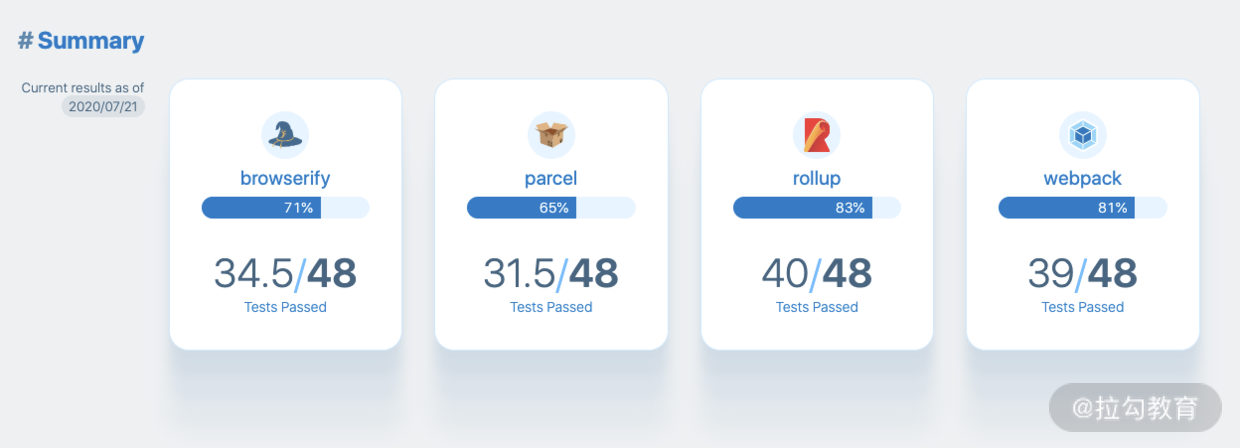
构建工具测评对比图
我们先看看评测数据:Rollup 得分最高,Parcel 得分最低,Webpack 和 Rollup 得分接近。测评通过的 test 得分只是一个方面,实际情况也和不同构建工具的设计目标有关。
比如,Webpack 的构建主要依赖了插件和 loader,因此它的能力虽然强大,但配置信息较为烦琐。而 Parcel 的设计目标之一就是零配置,开箱即用,但是在功能的集成上相对有限。
从横向发展来看,各大构建工具之间也在互相借鉴发展。比如,以 Webpack 为首的工具中,历史上编译构建速度较慢,即便监听文件启动增量构建,也无法解决初始时构建时间过长的问题。而 Parcel 主要内置了多核并行构建,利用多线程实现编译能力,在初始构建阶段就能获得较理想的构建速度。同时 Parcel 还内置了文件系统缓存,可以保存每个文件的编译结果。这一方面 Webpack 新版本(v5)也都有相应跟进。
因此,在构建工具的横向对比上,功能是否强大是一方面,而构建效率也将会是开发者考虑的核心指标。
那么对于构建工具来说,在一个现代化的项目中,哪些功能是“必备”的呢?从这些功能上,我们能学习到哪些基建和工程化知识呢?
我们还是从上面的分数出发,分析具体的测试维度。
这些分数来自以下 6 个维度的评测:
Code Splitting
Hashing
Importing Modules
Non-JavaScript Resources
Output Module Formats
Transformations

在 Code Splitting 方面,Rollup 表现最好,这是 Rollup 现代化的一个重要体现,而 Browserify 表层最差;
在 Hashing、Importing Modules 以及 Transformation 方面,各大构建工具表现相对趋近;
在 Output Module Formats 上,除了 Browserify,其他工具表现相对一致。
这里需要你深入思考:这 6 个维度到底是什么,为什么它们能作为考量指标被选取为评测参考标准?实际上,这个问题反映的技术信息是:一个现代化构建工具或构建方案,需要重点考量/实现哪些环节?
下面我们逐一进行分析。
Code Splitting
Code Splitting,即代码分割。这意味着在构建打包时,能够导出公共模块,避免重复打包,以及在页面加载运行时,实现最合理的按需加载策略。
实际上,Code Splitting 是一个很大的话题。比如:不同模块间的代码分割机制能否支持不同的上下文环境(Web worker 环境等特殊上下文情况),如何实现对 Dynamic Import 语法特性的支持,应用配置多入口/单入口时是否支持重复模块的抽取并打包,代码模块间是否支持 Living Bindings(如果被依赖的 module 中的值发生了变化,则会映射到所有依赖该值的模块中)。
Code Splitting 是现代化构建工具的标配,因为它直接决定了前端的静态资源产出情况,影响着项目应用的性能表现。这方面的更多内容,我将会在“代码拆分和按需加载:缩减 bundle size,把性能做到极致”一讲中深入分析。
Hashing
Hashing,即对打包资源进行版本信息映射。这个话题背后的重要技术点是最大化地利用缓存机制。我们知道有效的缓存策略将直接影响页面加载表现,决定用户体验。那么对于构建工具来说,为了实现更合理的 hash 机制,构建工具就需要分析各种打包资源,导出模块间依赖关系,依据依赖关系上下文决定产出包的哈希值。因为一个资源的变动,将会引起其依赖下游的关联资源变动,因此构建工具进行打包的前提就是对各个模块依赖关系进行分析,并根据依赖关系,支持开发者自行定义哈希策略(比如,Webpack 提供的不同类型 hash 的区别:hash/chunkhash/contenthash)。
这就涉及一个知识点:如何区分 Webpack 中的 hash/chunkhash/contenthash?
hash 反映了项目的构建版本,因此同一次构建过程中生成的 hash 都是一样的。换句话说,如果项目里某个模块发生更改,触发项目的重新构建,那么文件的 hash 值将会相应地改变。
如果使用 hash 策略,存在一个问题:即使某个模块的内容压根没有改变,但是重新构建后会产生一个新的 hash 值,使得缓存命中率较低。
针对以上问题,chunkhash 和 contenthash 就不一样了,chunkhash 会根据入口文件(Entry)进行依赖解析。
contenthash 则会根据文件具体内容,生成 hash 值。
我们来具体分析下,假设我们的应用项目中做到了把公共库和业务项目入口文件区分开单独进行打包,采用 chunkhash 策略,如果改动了业务项目入口文件,就不会引起公共库的 hash 值改变。对应以下示例:
entry:{
main: path.join(__dirname,'./main.js'),
vendor: ['react']
},
output:{
path:path.join(__dirname,'./build'),
publicPath: '/build/',
filname: 'bundle.[chunkhash].js'
}
我们再看一个例子,在 index.js 中出现了对 index.css 的引用:
require('./index.css')
此时因为 index.js 和 index.css 具有依赖关系,所以共用相同的 chunkhash 值。如果 index.js 内容发生变化,index.css 即使没有改动,在使用 chunkhash 策略时,被单独拆分的 index.css 的 hash 值也发生了变化。如果想让 index.css 完全根据文件内容来确定 hash 值,就可以使用 contenthash 策略了。
实际上,Webpack 的 hash 策略已经变得比较完善和成熟了。更多内容我在这里只做启发和串联,其中具体的设计思路,你可以参考:Hash vs chunkhash vs ContentHash。
Importing Modules
Importing Modules,即依赖机制。当然它对于一个构建流程或工具来说非常重要,因为历史和设计原因,前端开发者一般要面对包括 ESM、CommonJS 等不同模块化方案。而一个构建工具的设计当然也就要兼容不同类型的 modules importing 方案。除此之外,由于 Node.js 的 npm 机制设计,构建工具也要支持对从 node_modules 引入公共包的支持。
Non-JavaScript Resources
Non-JavaScript Resources,是指对其他非 JavaScript 类型资源导入的支持能力。这里的 Non-JavaScript Resources 可以是 HTML 文档、CSS 样式资源、JSON 资源、富媒体资源等。这些资源也是构成一个应用的关键内容,构建流程/工具当然要进行理解和支持。
Output Module Formats
Output Module Formats 对应上面的 Importing Modules 话题。构建输出内容的模块化方式也需要更加灵活,比如开发者可配置 ESM、CommonJS 等规范的构建内容导出。这方面内容我也会在“现代化前端开发和架构生态篇”中带你做更深入的分析。
Transformations
Transformations,现代化前端开发离不开编译/转义过程。比如对 JavaScript 代码的压缩、对无用代码的删除(DCE)等。这里需要注意的是,我们在设计构建工具时,对于类似 JSX 的编译、.vue 文件的编译,不会内置到构建工具当中,而是利用 Babel 等社区能力,“无缝融合”到构建流程里。构建工具只做构建分内的事情,其他扩展能力通过插件化机制来完成,显然是一个合理而必要的设计。
以上 6 个维度内容,都能展开作为一个独立且丰富的话题深入。设计这节内容是因为我希望你能从大局观上,对构建流程和构建工具要做哪些事情、为什么要做这些事情有一个更清晰的认知。你也可以在Tooling.Report中挖掘到更多内容。
总结
这一节我们从Tooling.Report入手,根据其集成分析的结果,横向对比了各大构建工具。
其实对比只是一方面,更重要的是我们需要通过对比结果,去了解各构建工具需要做哪些事情?基础建设和工程化要考虑哪些事情?搞清楚这些信息,我们就能站在更高的视角,进行技术选型,审视工程化和基础建设。下一讲,我将带你深入 Vite 实现源码,来了解当下前端构建工具的“风口浪尖”。
这里也给大家留一个思考题:Tooling.Report 的跑分代码是如何实现的?欢迎在留言区和我分享你的观点。我们下一讲再见。
# 精选评论
# **凯:
催更了
# 编辑回复:
每周一、三更新哈,争取把最好的内容呈现给大家~
# **用户3945:
刚好准备开展公司基建的工作,非常喜欢这些内容,有好多东西需要慢慢摸索和实践。
# **茏:
看的过程中我就在想这个测试是如何跑的。一个想法是准备多个标准项目,代表实际开发中项目的变动历史,然后对比同一工具对各个版本项目的打包结果,得到工具对项目变动的处理能力,比如hash问题。另一方面也要对比不同工具对同一项目的打包结果,以得到工具本身的打包能力,比如import/export的版本,这可能需要一个对应基准项目的标准打包结果
# **息:
老师的课好棒
# *俊:
个人也非常喜欢 web.dev 中 jake archibald 演讲的 tooling.report, 非常值得思考😁